Agora Code
git · by thebnbrkr
Persistent memory and codebase intelligence for AI coding agents, indexes symbols, tracks sessions, and exposes structured project knowledge through an MCP server so agents stop re-reading files and start building on what they already know.
No known CVEs
Apache-2.0 license
Maintained
Last commit 86d ago
Works with most clients
Transport: stdio, sse
1 tool · ~52 tok
Grade A · 0.0% of 200K ctx
Step 1
Install in your client
Config is the same across clients — only the file and path differ.
CD
Supported in Claude Desktopstdio, sse · Node 18+
Paste into ~/Library/Application Support/Claude/claude_desktop_config.json
{
"mcpServers": {
"agora-memory": {
"args": [
"memory-server"
],
"command": "agora-code"
}
}
}Are you the author?
Add this badge to your README to show your security score and help users find safe servers.
Embed in your READMEAbout badges →
[](https://mcppedia.org/s/agora-code)
Read me
What Agora Code does
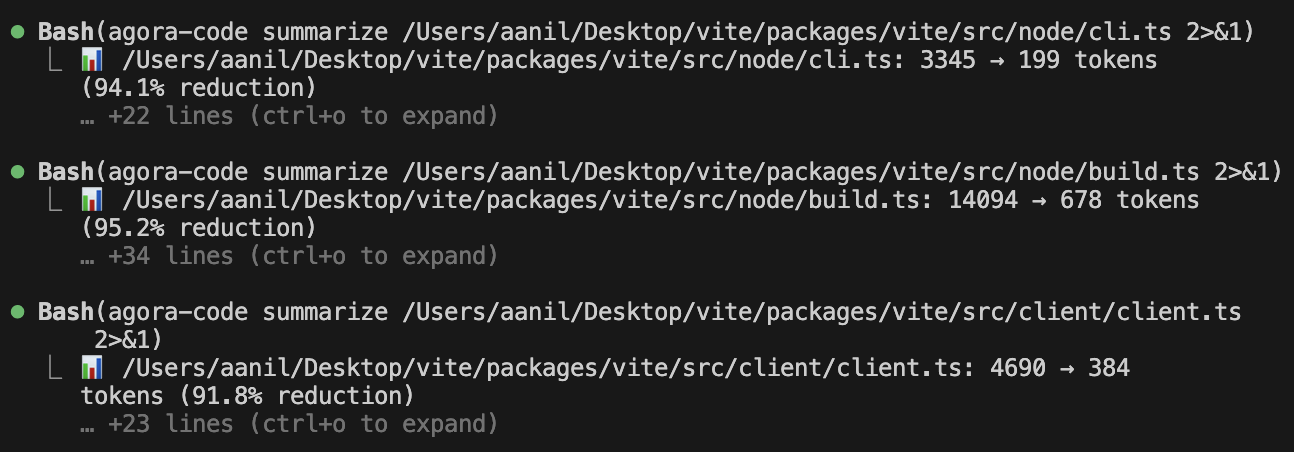
Persistent memory and context reduction for AI coding agents. Survives context window resets, new conversations, and agent restarts.
Test This Server
Run this in your terminal to verify the server starts. Then let us know if it worked — your result helps other developers.
uvx 'git' 2>&1 | head -1 && echo "✓ Server started successfully"
After testing, let us know if it worked:
Loading README…
Scored, not listed
Why this score
Five weighted categories — click any category to see the underlying evidence.
Score breakdown
83/100across 5 weighted dimensions
0255075100
30
8
20
15
10
−17
Security
Maintenance
Efficiency
Documentation
Compatibility
Categoriesclick a row to see evidence
Security
OSV.devNo known CVEs.
Checked git against OSV.dev.
Inventory
Tools (1)
Click any tool to inspect its schema.
~52 tokens total
Community
Reviews
Be the first to review
Have you used this server?
Share your experience — it helps other developers decide.
How easy was setup?Did it work reliably?How was the documentation?
Sign in to write a review.
Frequently Asked Questions
- Is Agora Code safe to use?
- Agora Code has no known CVEs as of the latest MCPpedia security scan. It does not require authentication, so any local process can connect — keep this in mind in shared environments. Licensed under Apache-2.0.
- How do I install Agora Code?
- Agora Code supports copy-paste install configs on its MCPpedia page for Claude Desktop, Cursor, and Claude Code. Scroll to the Quick Install section and select your client.
- What can Agora Code do?
- Agora Code provides 1 tool: memory-server. See the full tools list on the server page for descriptions and parameters.
- What AI clients work with Agora Code?
- Agora Code is compatible with claude-desktop, cursor, claude-code. It uses stdio and sse transport.
- Is Agora Code actively maintained?
- Agora Code is recently maintained — last commit was 86 days ago. It has 44 GitHub stars.
Related
Similar servers
Others in other
Compress tool outputs, logs, files, and RAG chunks before they reach the LLM. 60-95% fewer tokens, same answers. Library, proxy, MCP server.
55.0k 3
Pi Coding Agent extension (CLI-first) — routes bash/read/grep/find/ls through lean-ctx CLI for strong token savings. Optional MCP bridge can register advanced tools.
3.0k 6
AI travel agent — 1 smart MCP tool plus 62 compatibility aliases for flights, hotels, ground transport, price alerts. No API keys required.
43 1
I
io.github.levnikolaevich/hex-research-mcp92Research graph MCP for hypotheses, goals, runs, source quality, audits, and generated maps.
506 4
MCP Security Weekly
Get CVE alerts and security updates for Agora Code and similar servers.
Community
Discussion
Start a conversation
Ask a question, share a tip, or report an issue.
Has anyone used this with Cursor?How do you handle auth?Any alternatives?
Sign in to join the discussion.