RagWithMilvusTest
pymilvus · by NanGePlus
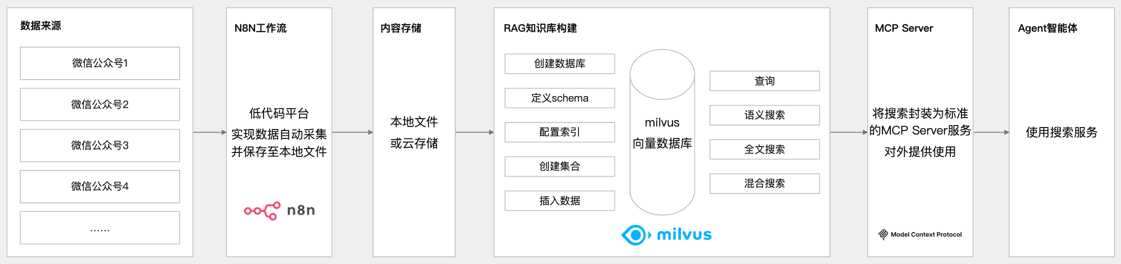
(1)使用低代码平台N8N实现对多个微信公众号文章进行自动采集并保存到本地文件 ; (2)使用主流的开源云原生向量数据库milvus将采集到的数据存储到知识库中并满足语义搜索、全文搜索及混合搜索; (3)将搜索功能封装为标准的MCP Server对外提供服务;(4)大模型(Agent)使用搜索MCP Server进行内容搜索
No known CVEs
MIT license
Stale
Last commit 270d ago
Works with most clients
Transport: stdio
1 tool · ~173 tok
Grade A · 0.1% of 200K ctx
Step 1
Install in your client
Config is the same across clients — only the file and path differ.
CD
Supported in Claude Desktopstdio · Node 18+
Paste into ~/Library/Application Support/Claude/claude_desktop_config.json
{
"mcpServers": {
"ragwithmilvustest": {
"args": [
"pymilvus"
],
"command": "uvx"
}
}
}Are you the author?
Add this badge to your README to show your security score and help users find safe servers.
Embed in your READMEAbout badges →
[](https://mcppedia.org/s/ragwithmilvustest)
Read me
What RagWithMilvusTest does
【从内容采集到智能搜索】全栈开源:手把手构建能理解业务逻辑的企业级AI搜索Agent,低代码采集 + 云原生向量库Milvus + MCP协议 + Agent https://www.bilibili.com/video/BV1whaqzzEK8/
Test This Server
Run this in your terminal to verify the server starts. Then let us know if it worked — your result helps other developers.
uvx 'pymilvus' 2>&1 | head -1 && echo "✓ Server started successfully"
After testing, let us know if it worked:
Loading README…
Scored, not listed
Why this score
Five weighted categories — click any category to see the underlying evidence.
Score breakdown
78/100across 5 weighted dimensions
0255075100
30
20
15
10
−22
Security
Maintenance
Efficiency
Documentation
Compatibility
Categoriesclick a row to see evidence
Security
OSV.devNo known CVEs.
Checked pymilvus against OSV.dev.
Inventory
Tools (1)
Click any tool to inspect its schema.
~173 tokens total
Community
Reviews
Be the first to review
Have you used this server?
Share your experience — it helps other developers decide.
How easy was setup?Did it work reliably?How was the documentation?
Sign in to write a review.
Frequently Asked Questions
- Is RagWithMilvusTest safe to use?
- RagWithMilvusTest has no known CVEs as of the latest MCPpedia security scan. It does not require authentication, so any local process can connect — keep this in mind in shared environments. Licensed under MIT.
- How do I install RagWithMilvusTest?
- RagWithMilvusTest supports copy-paste install configs on its MCPpedia page for Claude Desktop, Cursor, and Claude Code. Scroll to the Quick Install section and select your client.
- What can RagWithMilvusTest do?
- RagWithMilvusTest provides 1 tool: search. See the full tools list on the server page for descriptions and parameters.
- What AI clients work with RagWithMilvusTest?
- RagWithMilvusTest is compatible with claude-desktop, cursor, claude-code. It uses stdio transport.
- Is RagWithMilvusTest actively maintained?
- RagWithMilvusTest is less actively maintained — last commit was 270 days ago. It has 43 GitHub stars.
Related
Similar servers
Others in ai-ml / data
Query and manage PostgreSQL databases directly from AI assistants
87.1k 1
Persistent memory using a knowledge graph
87.1k 5
Dynamic problem-solving through sequential thought chains
87.1k 1
Manage Supabase projects — databases, auth, storage, and edge functions
2.7k 4
MCP Security Weekly
Get CVE alerts and security updates for RagWithMilvusTest and similar servers.
Community
Discussion
Start a conversation
Ask a question, share a tip, or report an issue.
Has anyone used this with Cursor?How do you handle auth?Any alternatives?
Sign in to join the discussion.