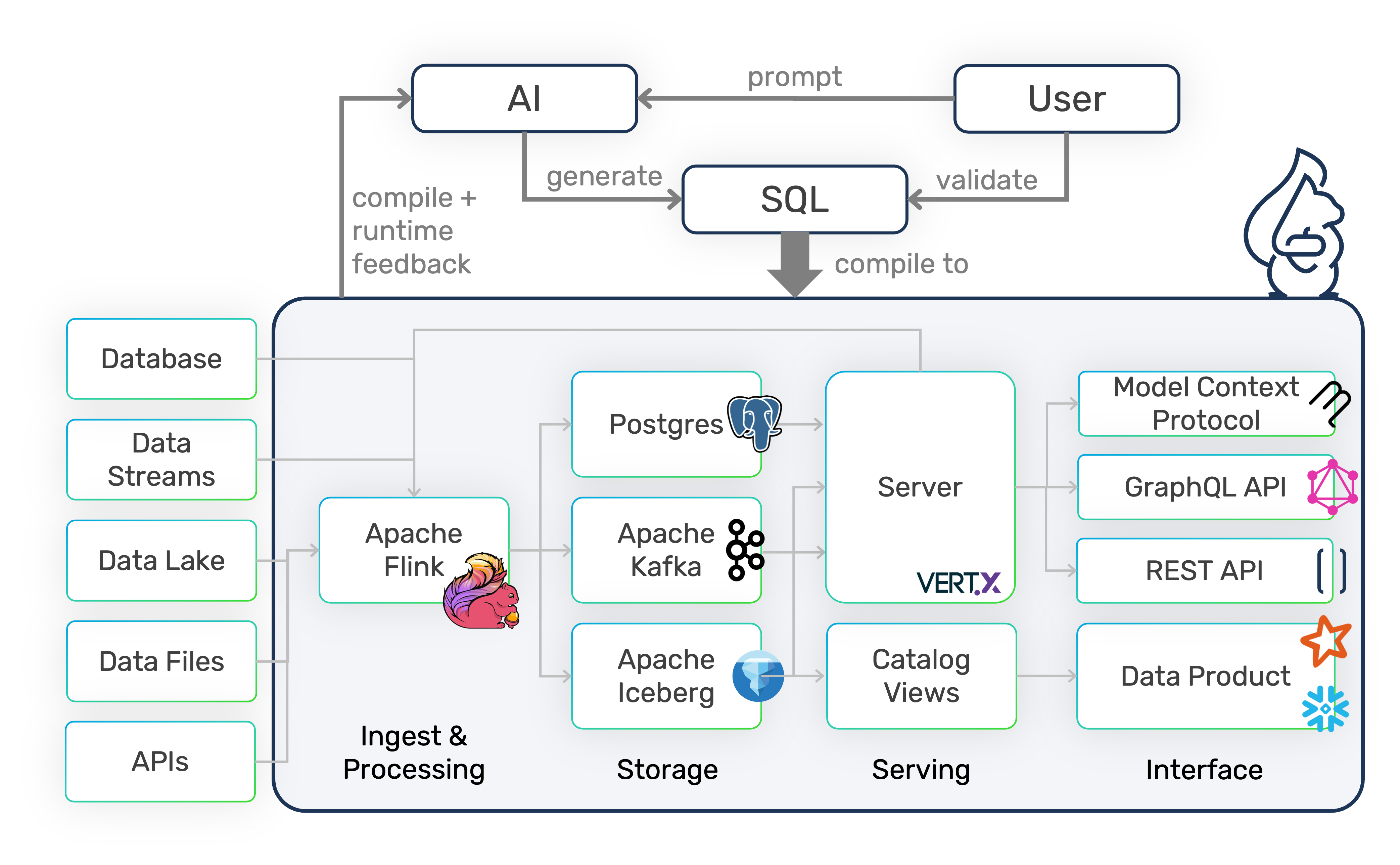
Sqrl
Data Pipeline Automation Framework to build MCP servers, data APIs, and data lakes with SQL.
ActiveNot tested
★ 210GitHub
34DNo CVEsactiveApache-2.0
Quick Install
{
"mcpServers": {
"sqrl": {
"command": "<see-readme>",
"args": []
}
}
}No install config available. Check the server's README for setup instructions.
Are you the author?
Add this badge to your README to show your security score and help users find safe servers.
Embed in your READMEAbout badges →
[](https://mcppedia.org/s/sqrl)
Should you use this server?
Data Pipeline Automation Framework to build MCP servers, data APIs, and data lakes with SQL.
✓
Is it safe?
No package registry to scan.
No authentication — any process on your machine can connect.
Apache-2.0. View license →
✓
Is it maintained?
Last commit 1 days ago. 210 stars.
i
Will it work with my client?
Transport: stdio. Works with Claude Desktop, Cursor, Claude Code, and most MCP clients.
Test This Server
No automated test available for this server. Check the GitHub README for setup instructions.
Score Breakdown
Security
6/30No known vulnerabilities.
○
Known CVEs — No package registry to scan
○
Tool safety — No tools to analyze
○
Tool poisoning — No tools to analyze
○
Injection vectors — No tools to analyze
✓
Tool stability — Tool definitions stable
○
Dependency health — No package to analyze
✓
License — License: Apache-2.0
○
Authentication — No authentication required
○